
mySql学习

mySql学习
晨梦学习教程参考
数据库概述
概念
数据库是按照数据结构来组织,存储和管理数据的仓库
数据库的具体体现就是磁盘的文件,或者内存的一段数据
可增删改查,可共享
存储设计规则(E-R模型)
E: 将一类数据存储到一张表中R: '表'和 '表' 可以维护某种关系,最终可以通过关系进行关联操作
库 --> 表 --> 列 --> 行
检验安装是否成功
windows为例:
安装数据库后 –> cmd 打开命令行工具【以管理员身份运行】
我的服务名称是 MySQL82
停止服务: net stop MySQL82
开启服务: net start MySQL82
确保服务是开启的后 输入命令 mysql【可以不用管理员身份运行】 来查看数据库是否配置到环境变量中
如果报:
‘mysql’ 不是内部或外部命令,也不是可运行的程序或批处理文件。
就没有配置成功 网上教程一大堆 按教程配置就好了,这里不过多阐述。
配置好:
C:\Users\Lenovo>mysql
ERROR 1045 (28000): Access denied for user ‘ODBC‘@’localhost’ (using password: NO)
学习顺序与目标
创建和修改盛放数据的容器(数据定义DDL)
表中添加、修改、删除数据(数据操纵DML)
表中数据多条件查询(数据查询DQL)
事务启动,提交和回滚(事务控制TCL)
账号创建,权限控制(数据控制DCL)
结构化查询语句SQL概述
链接mysql服务基础命令
1. mysql -u 用户名 -p -p 数据库名 -h 主机地址 -P 端口号用户名密码是必填项,其他的选填,且密码没空格,端口号的P大写
简单一点: mysql -u 用户名 -p
输入后会提示你输入密码。
2.查看数据库版本: select version();
3.注释:单行注释:#注释内容; 单行注释:-- 注释内容(有空格); 多行注释:/*注释内容*/
4. 退出 MySQL 命令行:EXIT; 或 QUIT;
可视化工具的选择和安装
MySQL Workbench Navicat SQLyog(我使用这个)一条数据的存储过程
在mysql中,一个完整的数据存储有4步 创建库——>定字段——> 创建表 ——>插数据SQL命名规定和规范
规定:
1.数据库名,表名不得超过30个字符
2.必须只能能包含A-Z,a-z,0-9,_共63个字符,且不能以数字开头
3.数据库名、表名、字段名等对象名中间不能包含空格
4.不重名,不使用关键字
规范(阿里巴巴规范手册):
1.注释应该清晰,简洁解释SQL语句的意图、功能和影响
2.库、表、列名应该使用小写字母,并使用_下划线或者驼峰命名。简洁明了、具有描述性
3.库名应于对应的程序名一致 例如:程序名为EcommercePlatform数据库就命名为ecommerce_platform_db
4.表命名最好是遵循 “业务名称_表”的作用,例如:alipay_task、force_project
5.列名应该遵循 ‘表实体_属性’的作用,例如:product_name
或者productName
库管理
创建库
- 基本语法: CREATE DATABASE 数据库名;
- 加判断防止重复创建(推荐):CREATE DATABASE IF NOT EXISTS 数据库名;
- 带字符集和排序规则:
CREATE DATABASE 数据库名
CHARACTER SET 字符集
COLLATE 排序规则;
字符集和排序规则是什么
字符集 推荐使用 utf8mb4,它是对 utf8 的升级,支持更多字符(如 emoji)。
排序规则 推荐使用
utf8mb4_0900_ai_ci 不区分大小写
utf8mb4_0900_as_cs 区分大小写
查看默认字符集和排序方式命令
SHOW VARIABLES LIKE ‘character_set_database’
SHOW VARIABLES LIKE ‘collation_database’
查看库
要操作表格和数据之前必须先说明是对哪个数据库进行操作,先use库
1.列出当前 MySQL 实例下的所有数据库:SHOW DATABASES;
2.查是否存在某个特定库:SHOW DATABASES LIKE ‘ddl_dl’;
3.查看当前使用库: SELECT DATABASE();
4.查看指定库下所有表: SHOW TABLES FROM 数据库名
5.查看创建库的信息: SHOW CREATE DATABASE 数据库名
6.切换库/选中库: use 数据库名
修改库
DATABASE不能改名。一些可视化工具可以改名,它是新建库,把所有表复制到新库,再删除旧库完成的 所以如果你想改名字,备份数据,删除旧库,创建新库,恢复数据即可 ALTER DATABASE 数据库名 CHARACTER SET 字符集 COLLATE 排序规则;删除库
删数据库要三思 ⚠️ 删除后数据不可恢复,一定要小心操作! 1.直接删除数据库:DROP DATABASE 数据库名; 2.安全写法 判断并删除库: DROP DATABASE IF EXISTS 数据库名;表管理
常用数据类型
| 类型 | 用途 | 示例 |
|---|---|---|
| TINYINT | -128-127 | 年龄、状态标志 |
| SMALLINT | 中等整数(-32,768 到 32,767) | 库存量 |
| INT | 标准整数(约±21亿) | 年龄、编号 |
| BIGINT | 大整数(超过21亿,最大约±9千万亿) | 用户ID、大额金额 |
| FLOAT | 单精度浮点数(近似小数) | 温度、身高 |
| DOUBLE | 双精度浮点数(更高精度的近似小数) | 科学计算、复杂测量 |
| DECIMAL(m,n) | 精确小数 | 价格、分数 |
| CHAR(n) | 固定长度字符串 | 定长字段:身份证号、性别代码、国家代码 |
| VARCHAR(n) | 可变长度字符串 | 变长字段(姓名、地址、描述) |
| TEXT | 大段文字 | 评论、描述、文章内容 |
| TIME | 时间(HH:MM:SS) | 上班打卡时间 |
| DATE | 日期 YYYY-MM-DD | 生日 |
| DATETIME | 日期 + 时间 YYYY-MM-DD HH:MM:SS | 注册时间、登录时间 |
| TIMESTAMP | 时间戳支持时区 YYYY-MM-DD HH:MM:SS | 创建时间、更新时间 |
| ENUM(…) | 枚举类型、限制在指定选项中 | 性别(男/女)、状态(启用/禁用) |
- 整数类型都可以添加unsigned修饰符,添加以后对应的数据就无负号了,值从0开始, 它必须紧贴类型后放置
- CHAR 固定长度,存的时候补空格,读的时候砍空格。
- VARCHAR 变长度,存多少算多少,空格原样保存。
- ENUM 是让字段值只能在规定的选项里选,比如性别只能是”男”或”女”
- 确定数据范围,选择符合的且储存空间占用最小的类型;不确定范围的,选择范围较大的类型,避免值超出范围异常
插入时不用管,更新时也不用管,自动搞定时间:
TIMESTAMP | DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '插入时自动写'
TIMESTAMP | DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '插入&更新都自动写'表创建
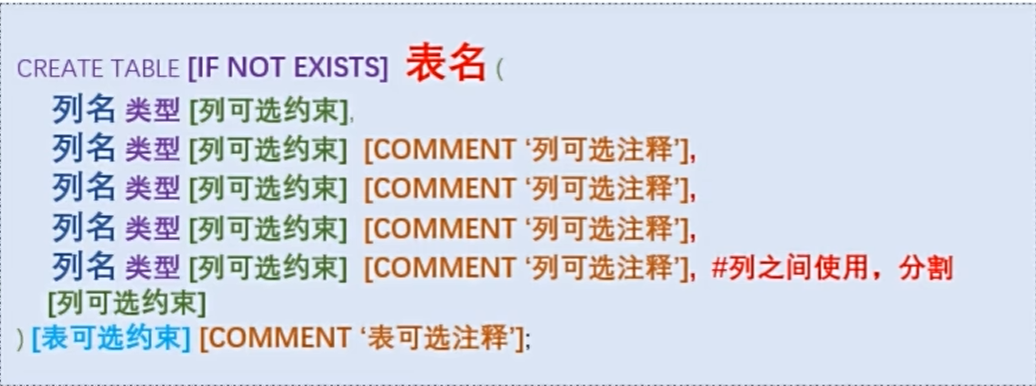
关键点1: 表名、列名、类型必须填写,其他可选
关键点2: 推荐使用if not exists, 直接创建存在报错
关键点3: 注释不是必须的,但是很有必要的
关键点4: 列之间使用,分割
验证: 查看某个库下的全部表 SHOW TABLES FORM 数据库名
例子:
CREATE DATABASE book_libs CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_cs;
USE book_libs
CREATE TABLE IF NOT EXISTS books (
book_name VARCHAR(20) COMMENT '图书名称',
book_price DECIMAL(4,1) COMMENT '图书价格',
book_num INT
) CHARSET = utf8mb4 COMMENT '图书表';
SHOW TABLES FROM book_libs
表修改
1.添加新字段【在表里加新的一列】:
ALTER TABLE 表名 ADD 列名 类型 COMMENT ‘注释’;
2.修改字段类型或名字【修改列的类型,或者改列的名字】:
ALTER TABLE 表名 MODIFY 列名 新类型 COMMENT ‘注释’;
ALTER TABLE 表名 CHANGE 旧列名 新列名 新类型 COMMENT ‘注释’;
3.删除字段【删除一列】:
ALTER TABLE 表名 DROP COLUMN 列名;
4.修改表名【改表的名字】:
ALTER TABLE 旧表名 RENAME TO 新表名;
5.修改表的注释【给整张表改备注】:
ALTER TABLE 表名 COMMENT = ‘新注释’;
5.删除表:
DROP TABLE IF EXISTS 数据表1[,数据表2,…,数据表n];
5.清空表数据:
TRUNCATE TABLE 表名;
数据操纵语言概述(DML)
插入数据语法
数据操作的最基本单位是行,按行进行增删改查
为表的一行指定字段(列) 插入数据
INSERT INTO 表名(列名1,列名2…) VALUES(value1,value2…);
同时插入多条记录
INSERT INTO 表名 VALUES(value1,value2),…,(value1,value2…);
或者
INSERT INTO 表名(列名1,列名2…) VALUES(value1,value2…),…,(value1,value2…);
值的数量要等于表指定列的数量
值的类型和顺序要和[指定列的顺序]一一对应
修改数据语法
修改表中所有行数据(全表修改)
不添加where,代表修改一个表中所有行的数据
UPDATE table_name SET column1 = value1,column2 = value2,…
修改表中符合条件行的数据(条件修改)
条件修改只是在后面添加where,where后面指定相关的条件即可
UPDATE table_name SET column1 = value1,column2 = value2,… WHERE condition
删除数据语法
删除表中所有行数据(全表删除)
DELETE FROM table_name;
删除表中符合条件行的数据(条件删除) 且是 AND 或是 OR
DELETE FROM table_name[WHERE condition]
数据查询语句(DQL)
基础SELETE的五种情况
- 只读 ,不会修改数据,影响库表结构 - 会基于原表数据查询出一个虚拟库 - 用于获取表中的数据记录,支持条件筛选,排序,分页,分组等操作常用关键字:SELECT
1.单表查询: 单张真实表 ——> 查询语法 ——> 虚拟表
2.多表查询: 多张真实表 ——> 合并语法 ——> 中间虚拟表 ——> 查询语法 ——> 虚拟表
注意:以下 SELECT 查询只是“读取”数据,不会对原始表结构或数据造成影响。具有 临时性 非持久化 不改原表 每次刷新/执行都重新生成 服务于展示和输出
意义:用于构造测试数据或临时表
场景 1:非表查询
解释: 利用 select 关键字,快速输出一个运算结果或者函数,类似 java 控制台输出
语法: select 运算,函数
查询当前时间: SELECT NOW();场景 2: 指定表查询结果
解释: 查询的时候,结果来自于一张表或者多表
语法: select 查询表中的哪些列 列名,列名,列名 from 参照的表名
select 表名.列名,列名,列名 from 参照的表名 (多表的时候,需要这么做,多表的列名可能重复)
select * from 表名 *就是表中所有列
查询全部员工信息:SELECT * FROM 员工表;
查询全部员工姓名和工资:SELECT ename,salary FROM 员工表;场景 3:指定列并且起名字
解释: 查询的时候可以给列起别名,为了匹配后期 java 数据格式
语法: SELECT 列名 as 别名, 列名 别名 from 表名
查询全部员工姓名和工资,名字显示为 name 名称: ;
SELECT ename AS NAME,salary FROM 员工表
SELECT ename NAME,salary FROM 员工表;场景 4:去掉重复行数据
解释: 根据结果进行重复值去重
语法: SELECT DISTINCT 列名, 列名, 列名 from 表名;
查询员工的性别种类: SELETE DISTINCT gender FROM 员工表场景 5:查询常数列
解释: 人为制造的一个值和一个列 (多个值,多个列)
语法: SELECT DISTINCT 列, 列名, ‘值’ as 列名 from 表名;
查询员工姓名和工资,并添加一个公司 company 为尚硅谷
SELECT ename AS NAME, salary, ‘尚硅谷’ AS company FROM 员工表;扩展:ifnull(列,为 null 给予的默认值)例如 SELECT ename NAME 名字,IFNULL(salary,0) 奖金 FROM 员工表;
表结构和WHERE过滤
1.显示表结构: 使用命令查看表中的列和列的特征: DESC 表名2.过滤数据(条件查询) where添加以后,就不是全表查询,先过滤条件,符合,再返回指定列
语法
SELECT 字段列表
FROM 表名
[WHERE 条件(and or xor)]
[GROUP BY 分组字段]
[HAVING 分组条件]
[ORDER BY 排序字段]
[LIMIT 限制数量];
示例
SELECT name, age
FROM users
WHERE age > 18
ORDER BY age DESC
LIMIT 10;
上面语句从 users 表中筛选出年龄大于 18 的用户,按年龄降序排列,取前 10 条,最终返回的是一张虚拟表。
常见数据库运算符分类与用法
这里只演示我不记不住的 字符串和数字会自动相互转换 不需要考虑类型 '1'= 1 为true| 运算符 | 说明 | 示例 |
|---|---|---|
| != 或 <> | 不等于 | WHERE gender <> ‘男’ |
| BETWEEN … AND … | 区间 | WHERE salary BETWEEN 5000 AND 10000 |
| IN (…) | 多个匹配值 | WHERE dept IN (‘销售部’, ‘开发部’) |
| NOT IN (…) | 不在其中 | WHERE id NOT IN (1, 2, 3) |
| IS NULL 或 IS NOT NULL | 是否为空 | WHERE bonus IS NULL |
| AND | 与,同时满足 | WHERE age > 18 AND gender = ‘女’ |
| OR | 或,满足一个 | WHERE name = ‘张三’ OR name = ‘李四’ |
| XOR | 异或 | WHERE name = ‘张三’ XOR name = ‘李四’ |
| NOT | 非,取反 | WHERE NOT (age < 18) |
| + - * / % DIV | 加减乘除取余 DIV 为整除除法 | SELECT quantity * price FROM orders |
| LIKE | 模糊匹配 | WHERE name LIKE ‘张%’(以“张”开头) |
| _ | 匹配一个任意字符 | WHERE code LIKE ‘A_1’(A 开头,中间任意 1 位字符,1 结尾) |
| % | 匹配任意多个字符 | LIKE ‘%工程师’(以“工程师”结尾) |
| NOT LIKE | 不匹配 | WHERE email NOT LIKE ‘%.com’ |
三元运算 / 判断运算(高级):CASE WHEN THEN ELSE END
SELECT ename,
CASE
WHEN salary >= 10000 THEN '高薪'
WHEN salary >= 5000 THEN '中薪'
ELSE '低薪'
END AS 薪资等级
FROM employees;
内置函数
单行函数
对查询结果中的每一行数据单独操作,一行输入 → 一行输出,不会改变行数。- 字符串函数
MYSQL 中,字符串的位置是从 1 开始的
| 函数 | 功能 | 示例 |
|---|---|---|
| LENGTH(str) | 返回的是 字节数 | SELECT LENGTH(‘你好’); → 6(每个汉字 3 字节,utf8 编码) |
| CHAR_LENGTH(字符) | 返回字符串数 | SELECT CHAR_LENGTH(‘你好’); → 2 |
| CONCAT(a, b) | 拼接字符串 | SELECT CONCAT(‘陈’, ‘小 Q’); → 陈小 Q |
| SUBSTRING(str, start, length) | 截取子串 | SELECT SUBSTRING(‘abcdef’, 2, 3); → bcd |
| LOWER(str) / UPPER(str) | 转小写 / 大写 | SELECT LOWER(‘AbC’); → abc |
| REPLACE(str, from, to) | 替换子串 | SELECT REPLACE(‘abcabc’, ‘a’, ‘x’); → xbcxbc |
- 数值函数
| 函数 | 功能 | 示例 |
|---|---|---|
| ABS(x) | 绝对值 | SELECT ABS(-5); → 5 |
| CEIL(x) / FLOOR(x) | 向上/向下取整 | CEIL(3.2) → 4, FLOOR(3.8) → 3 |
| ROUND(x, d) | 四舍五入到 d 位小数 | ROUND(3.14159, 2) → 3.14 |
| TRUNCATE(x, y) | 返回数字 x 截取为 y 位小数的结果 | TRUNCATE(3.14159, 1) → 3.1 |
| RAND() | 不带参数返回一个不同的随机数(0 到 1 之间) 带参数 每次生成的随机数都一样 | SELECT RAND(); → 0.726348272 |
- 日期函数
| 函数 | 功能 | 示例 |
|---|---|---|
| NOW() | 返回当前系统日期和时间 | SELECT NOW(); → 2025-05-13 10:00:00 |
| CURDATE() | 返回当前日期,只包括年月日 | SELECT CURDATE(); → 2025-05-13 |
| CURTIME() | 返回当前时间(仅时分秒) | SELECT CURTIME(); → 10:00:00 |
| DATE() | 只提取日期部分 | SELECT DATE(NOW()); → 2025-05-13 |
| YEAR() / MONTH() / DAY() / WEEK(date) | 提取年/月/日/第几周 周日为一周起始 | SELECT WEEK(NOW()); → 20 |
| WEEKDAY(date) / DAYOFWEEK(date) | 返回一周的第几天(0=周一,6=周日)/ 返回一周的第几天(1=周日,7=周六) | SELECT WEEKDAY(NOW()); → 1 / SELECT DAYOFWEEK(NOW()); → 3 |
| DATEDIFF(d1, d2) | 计算两个日期差 | DATEDIFF(‘2025-05-13’, ‘2025-05-01’) → 12 |
| DATE_FORMAT(date, format) | 将日期格式化为指定格式的字符串 | SELECT DATE_FORMAT(NOW(), ‘%Y-%m-%d %H:%i:%s’); 结果示例:’2025-05-14 10:23:45’ |
| STR_TO_DATE(str, format) | 将字符串按照指定格式解析为日期。 | SELECT STR_TO_DATE(‘2025-05-14 10:23:45’, ‘%Y-%m-%d %H:%i:%s’); |
- 控制函数(条件)
| 函数 | 功能 | 示例 |
|---|---|---|
| IF(condition, true, false) | 条件判断 | SELECT IF(1 > 0, ‘是’, ‘否’); → 是 |
| CASE WHEN THEN ELSE END | 多条件判断 | SELECT CASE WHEN score >= 90 THEN ‘优’ ELSE ‘良’ END |
多行函数
对整列或分组数据进行统计运算,一组数据输入 → 一个结果输出,常与 GROUP BY 搭配。| 函数 | 功能 | 示例 |
|---|---|---|
| COUNT(*) | 统计记录总数 如果是列名就是列非空值出现的次数 | SELECT COUNT(列名/*/1) FROM emp; |
| SUM(col) | 求和 | SELECT SUM(salary) FROM emp; |
| AVG(col) | 平均值 | SELECT AVG(salary) FROM emp; |
| MAX(col) | 最大值 | SELECT MAX(salary) FROM emp; |
| MIN(col) | 最小值 | SELECT MIN(salary) FROM emp; |
举个例子:
SELECT dept_id, AVG(salary) AS avg_salary
FROM emp
GROUP BY dept_id;
注意:
多行函数不能直接出现在 WHERE 子句中,需用 HAVING。
若混用普通字段与聚合函数,必须 GROUP BY。







